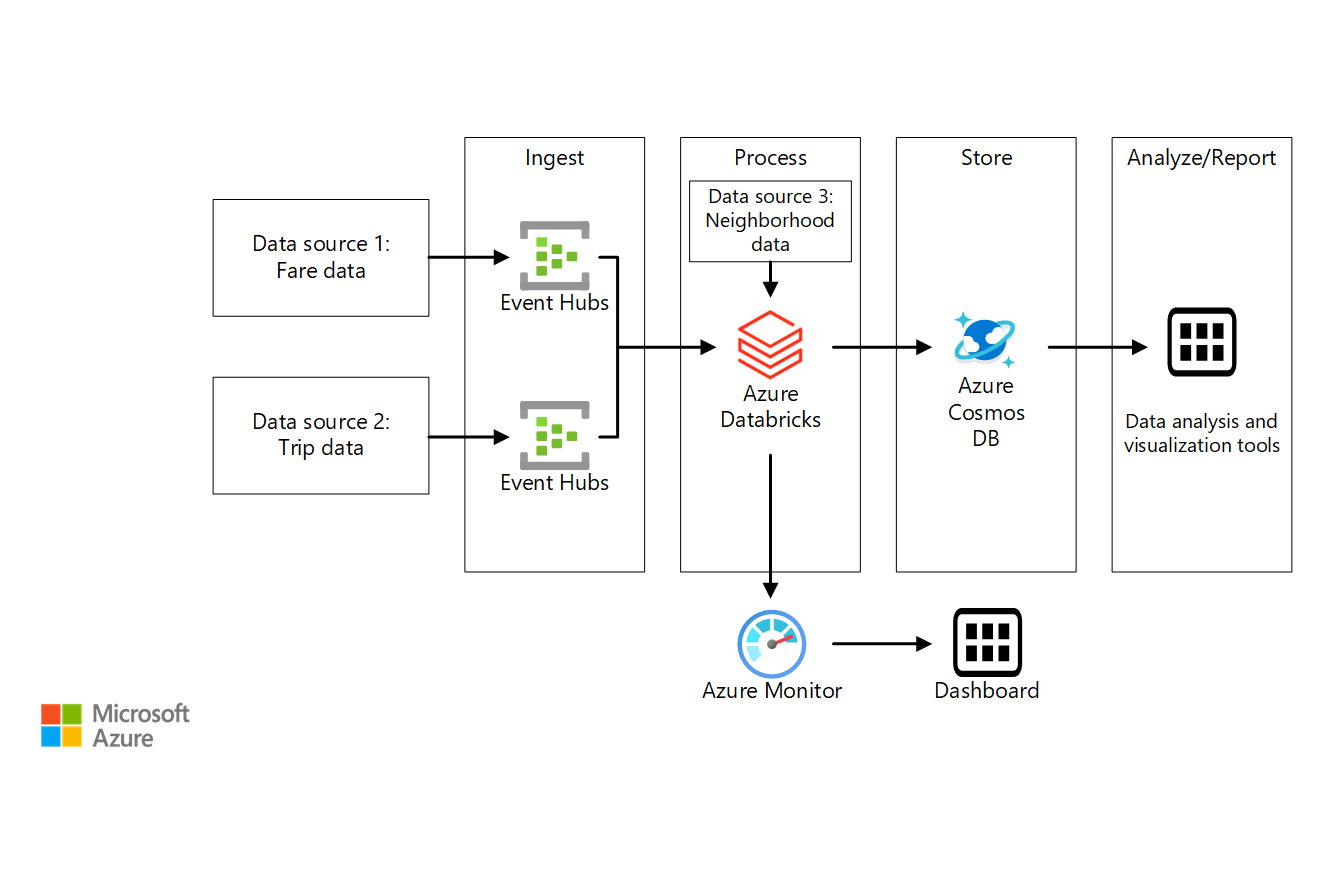
Data pipeline runs completely in memory. The data processing pipeline service consists of analysis pipelines and execution infrastructure that move raw data through analysis producing measurements that are ingested into the data store for storage and download by the community. Big data processing pipelines.
data processing pipelines

In most cases theres no need to store intermediate results in temporary databases or files on disk.
Data processing pipelines. This technique involves processing data from different source systems to find duplicate or identical records and merge records in batch or real time to create a golden record which is an example of an mdm pipeline. Most big data applications are composed of a set of operations executed one after another as a pipeline. Data matching and merging is a crucial technique of master data management mdm. Processing of raw data from modern astronomical instruments is nowadays often carried out using dedicated software so called pipelines which are largely run in automated operation.
For citizen data scientists data pipelines are important for data science projects. Rna seq rampage 1 chip seq dnase seq atac seq 2 and wgbs. The encode data coordinating center has developed data processing pipelines for major assay types generated by the project. But with data coming from numerous sources in varying formats stored across cloud serverless or on premises infrastructures data pipelines are the first step to centralizing data for reliable business intelligence operational insights and analytics.
All data processing pipeline code is available from the encode dcc github and the pipelines can be run interactively from a featured project on the dnanexus cloud computing platform. Processing data in memory while it moves through the pipeline can be more than 100 times faster than storing it to disk to query or process later. Learn what a data pipeline is architecture basics. As new single cell.
Data uncovers deep insights enhances efficient processes and fuels informed decisions. Data flows through these operations going through various transformations along the way. In this paper we describe the data reduction pipeline of the multi unit spectroscopic explorer muse integral field spectrograph operated at esos paranal observatory. The hca dcp stores both the submitted raw data and data resulting from data processing and each type is available for download.
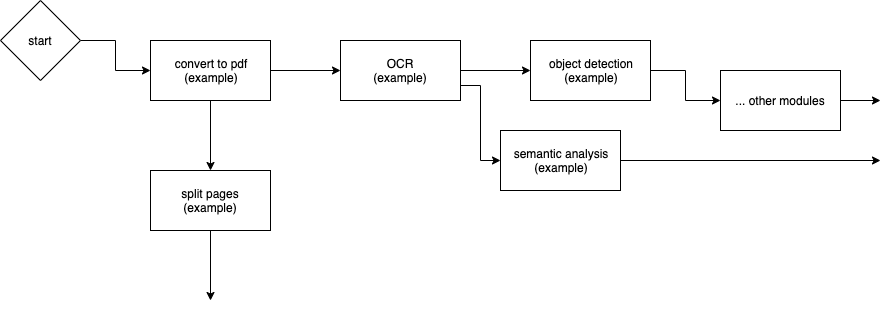
We also call this dataflow graphs.